Recently, a research group led by Prof. WANG Quan from Xi'an Institute of Optics and Precision Mechanics of the Chinese Academy of Sciences proposed a novel deep network which overcomes the limitations of reported model-driven methods and data-driven methods, achieving efficient video compressive imaging. The study was published in Signal Processing.
As one of the most promising strategies to achieve high-speed imaging with relatively low hardware cost, video snapshot compressive imaging (VSCI) has received widespread attention. However, current algorithms still confront with insufficient representation capacity, unsatisfied accuracy, and limited compression rates.
Therefore, the researchers proposed a novel degradation-aware deep unfolding network (DADUN) for VSCI reconstruction, which can leverage the benefits of previously reported methods while mitigating their weaknesses.
In specific, the MAP energy model was adopted to avoid reliance of DADUN on intricate prior knowledge. Moreover, the informative parameters, prior information, and physical mask were employed in implicitly estimations, which can distinguish the DADUN from previous deep unfolding methods.
The researchers found that the proposed model can achieves superior reconstruction accuracy and enhanced visual quality compared to state-of-the-art methods in the experiments where grayscale simulation video, color simulation video, and real snapshot compressive imaging video data were employed for testing.
"The proposed model shows the effectiveness in various video sequences, which is also robust to random masks and has wide generalization bounds," said Prof. WANG Quan.
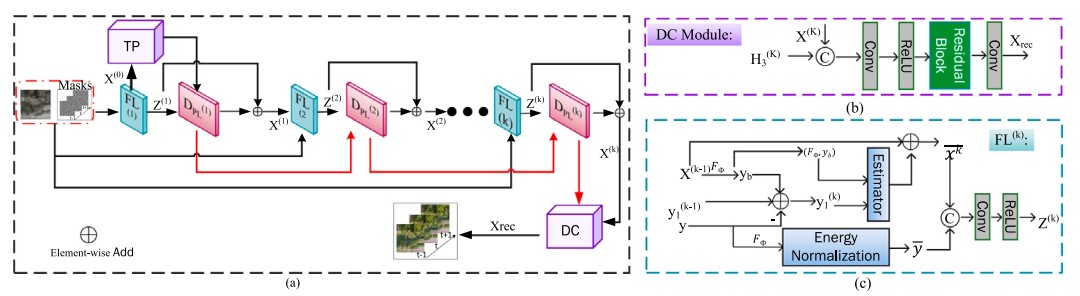
Fig. The proposed DADUN network and the overall iterative process. (Image by XIOPM)
Download: