Images are considered as the main source for people to perceive the world, however, not suitable for visually impaired people (e.g. blind, have low vision). The traditional way attempts to solve this by training them to activating their visual cortex using auditory messages, which is still not practical as this method takes lots of time.
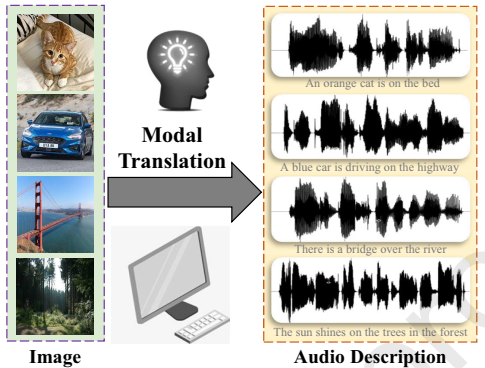 Fig. 1 The schematic diagram of the image-to-audio-description task
Fig. 1 The schematic diagram of the image-to-audio-description task
Recently, Prof. LU Xiaoqiang from Xi’an Institute of Optics and Precision Mechanics(XIOPM), Chinese Academy of Sciences(CAS) proposed a new method to achieve the image-to-audio-description (I2AD) task using cross-modal generation, where its main idea is shown in Fig.1.
Different from the current cross-modal retrieval task which only needs to retrieve samples that exist in a database, the I2AD task requires learning a complex generative function that produces meaningful outputs. In other words, the I2AD task is not only to understand the content of the input image but also to translate the information contained in the image as an intelligible natural language in audio form (audio description).
To solve the problem, the researchers proposed a modal translation network (MT-Net) which includes three progressive sub-networks: 1) feature learning, 2) cross-modal mapping, and 3) audio generation. The feature learning step aims to learn the feature of image and audio respectively, then the cross-modal mapping step transforms the image feature into a cross-modal representation that accounts for the audio feature. Finally, the audio generation step generates the audio waveform from the cross-modal representation. The structure of the network is shown in Fig.2.
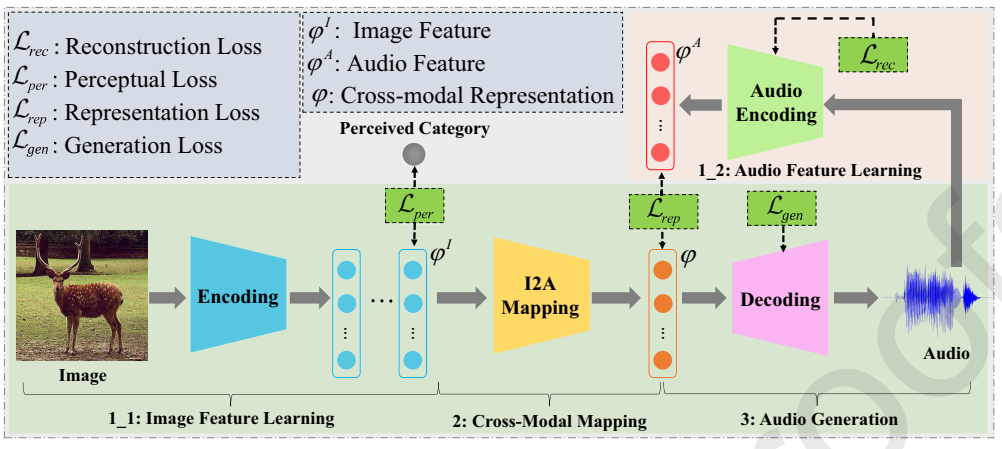 Fig. 2 The proposed network
Fig. 2 The proposed network
As this is the first attempt to study the I2AD task, 3 large-scale datasets are built as test datasets, and the results verified the feasibility and the effectiveness of the proposed method.
 Fig. 3 The qualitative results of the proposed MT-Net.
Fig. 3 The qualitative results of the proposed MT-Net.
The results were published in a paper in Neurocomputing.