Human action recognition based on skeleton has played a key role in various computer vision-related applications, such as smart surveillance, human-computer interaction, and medical rehabilitation.
However, due to various viewing angles, diverse body sizes, and occasional noisy data, etc., this remains a challenging task. The existing deep learning-based methods require long time to train the models and may fail to provide an interpretable descriptor to code the temporal-spatial feature of the skeleton sequence.
In this paper, a key-segment descriptor and a temporal step matrix model to semantically present the temporal-spatial skeleton data are proposed by a research team led by Prof. Dr. SONG Zongxi from Xi'an Institute of Optics and Precision Mechanics (XIOPM) of the Chinese Academy of Sciences (CAS).
First, a skeleton normalization is developed to make the skeleton sequence robust to the absolute body size and initial body orientation. Second, the normalized skeleton data is divided into skeleton segments, which are treated as the action units, combining 3D skeleton pose and the motion. Each skeleton sequence is coded as a meaningful and characteristic key segment sequence based on the key segment dictionary formed by the segments from all the training samples. Third, the temporal structure of the key segment sequence is coded into a step matrix by the proposed temporal step matrix model, and the multiscale temporal information is stored in step matrices with various steps.
Experimental results on three challenging datasets demonstrate that the proposed method outperforms all the hand-crafted methods and it is comparable to recent deep learning-based methods.
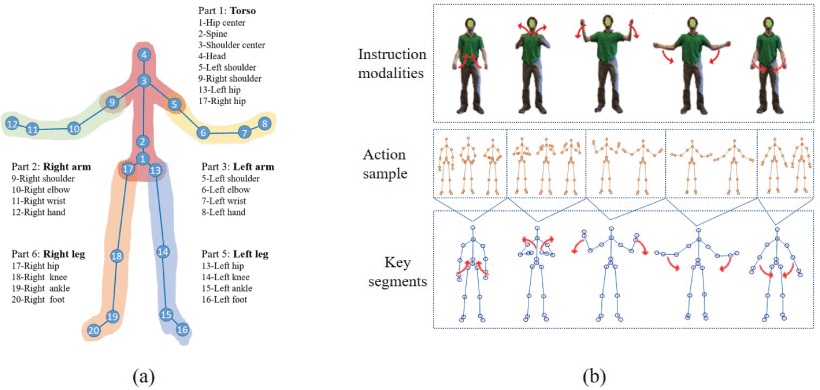 Skeleton model adopted by Kinect1 and action “Wind up the music” in the MSRC-12 dataset. (Image by XIOPM)
Skeleton model adopted by Kinect1 and action “Wind up the music” in the MSRC-12 dataset. (Image by XIOPM)
(Original research article " IEEE ACCESS (2019) https://doi.org/10.1109/ACCESS.2019.2954744")